Ruby Programming Training Classes in Providence, Rhode Island
Learn Ruby Programming in Providence, RhodeIsland and surrounding areas via our hands-on, expert led courses. All of our classes either are offered on an onsite, online or public instructor led basis. Here is a list of our current Ruby Programming related training offerings in Providence, Rhode Island: Ruby Programming Training
Ruby Programming Training Catalog
Course Directory [training on all levels]
- .NET Classes
- Agile/Scrum Classes
- AI Classes
- Ajax Classes
- Android and iPhone Programming Classes
- Azure Classes
- Blaze Advisor Classes
- C Programming Classes
- C# Programming Classes
- C++ Programming Classes
- Cisco Classes
- Cloud Classes
- CompTIA Classes
- Crystal Reports Classes
- Data Classes
- Design Patterns Classes
- DevOps Classes
- Foundations of Web Design & Web Authoring Classes
- Git, Jira, Wicket, Gradle, Tableau Classes
- IBM Classes
- Java Programming Classes
- JBoss Administration Classes
- JUnit, TDD, CPTC, Web Penetration Classes
- Linux Unix Classes
- Machine Learning Classes
- Microsoft Classes
- Microsoft Development Classes
- Microsoft SQL Server Classes
- Microsoft Team Foundation Server Classes
- Microsoft Windows Server Classes
- Oracle, MySQL, Cassandra, Hadoop Database Classes
- Perl Programming Classes
- Python Programming Classes
- Ruby Programming Classes
- SAS Classes
- Security Classes
- SharePoint Classes
- SOA Classes
- Tcl, Awk, Bash, Shell Classes
- UML Classes
- VMWare Classes
- Web Development Classes
- Web Services Classes
- Weblogic Administration Classes
- XML Classes
- Docker
17 August, 2026 - 19 August, 2026 - AWS Certified Machine Learning: Specialty (MLS-C01)
2 November, 2026 - 6 November, 2026 - ASP.NET Core MVC, Rev. 8.0
19 October, 2026 - 20 October, 2026 - RED HAT ENTERPRISE LINUX SYSTEMS ADMIN II
2 November, 2026 - 5 November, 2026 - OpenShift Fundamentals
5 October, 2026 - 7 October, 2026 - See our complete public course listing
Blog Entries publications that: entertain, make you think, offer insight
As much as we love to assume free Wi-Fi is secure, this is far from the truth. Because you are attaching to a service many others are connected to as well, without security measures, your device can be hacked, especially if the network is unencrypted. Because this encryption involves handing out a 26-character hexadecimal key to every individual wanting to use that network, most places opt for ease of access over security. And even with a secure network, your information is vulnerable to everyone else who has the password and is on the network.
This may not seem like such a big deal and many people don’t believe they have anything to hide on their personal devices, but remember what you use on those devices. Chances are your e-mail is attached as well as all other social media sites. You may have apps that track your finances or private messages to certain others that you would never want anyone else to see. Luckily, there are steps that can be taken to reduce and prevent any unwanted information grabbers from accessing your personal information.
To start, go through your computer’s settings in order to verify your operating system’s security functions are all set to offer the highest protection. Open up the Control Panel and double check that your Firewall is enabled for both private and public networks. Then, go to Network and Sharing to open Change advanced sharing settings. In here, you can turn off file and printer sharing and network discovery for public networks.
One of the most important things to watch for is HTTPS. Hypertext Transfer Protocol Secure ensures secure communication across the web. Many of the major email systems use this when you log in (as another layer of password protection) but drop the security as soon as the login is complete. To keep this going, HTTPS Everywhere is a browser extension that gives you a secure connection when browsing some of the more popular sites. It can also be programmed for other sites you like to visit that don’t use HTTPS.
Not every place on the internet provides the choice of HTTPS, and VPNs are there to fill in the security gap. Virtual Private Networks allows data to be sent and received through public access points as if it were directly connected to a secure network. Many businesses offer this for company devices, but if you are an individual looking for that kind of security, ProXPN is a free version that can be upgraded. Unfortunately, it limits your speed, but other choices include VPNBook, OpenVPN Shield Exchange, and OkayFreedom.
With these three steps implemented, secure public Wi-Fi can be achieved. No longer will you have to worry about connecting in an unsure environment with strangers, never knowing if your information is being stolen. With all of the options free of charge, it is also an affordable means of protecting yourself that only takes a little time and effort to implement and guarantee safety.
Net Neutrality for the Layperson
What are a few unique pieces of career advice that nobody ever mentions?
Information Technology is one of the most dynamic industries with new technologies surfacing frequently. In such a scenario, it can get intimidating for information technology professionals at all levels to keep abreast of the latest technology innovations worth investing time and resources into.
It can therefore get daunting for entry and mid-level IT professionals to decide which technologies they should potentially be developing skills. However, the biggest challenge comes for senior information technology professionals responsible for driving the IT strategy in their organizations.
It is therefore important to keep abreast of the latest technology trends and get them from reputable sources. Here are some of the ways to keep on top of the latest trends in Information Technology.
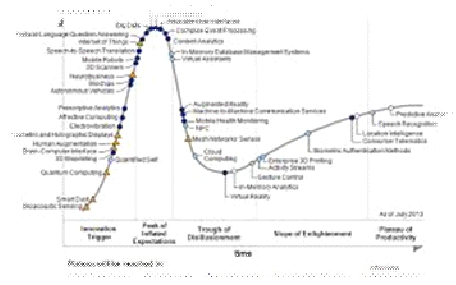
· Subscribe to leading Analyst Firms: If you work for a leading IT organization, chances are that you already have subscription to leading IT analyst firms notably Gartner and Forrester. These two firms are some of the most recognized analyst firms with extensive coverage on almost every enterprise technology including hardware and software. These Analyst firms frequently publish reports on global IT spending and trends that are based on primary research conducted on vendors and global CIOs & CTOs. However, subscription to these reports is very expensive and if you are a part of a small organization you may have issues securing access to these reports. One of the most important pieces of research published by these firms happens to be the Gartner Hype Cycle which plots leading technologies and their maturity curve.Even if you do not have access to Gartner research, you can hack your way by searching for “Gartner Hype Cycle” on Google Images and you will in most cases be able to see the plots similar to the one below
Over time, companies are migrating from COBOL to the latest standard of C# solutions due to reasons such as cumbersome deployment processes, scarcity of trained developers, platform dependencies, increasing maintenance fees. Whether a company wants to migrate to reporting applications, operational infrastructure, or management support systems, shifting from COBOL to C# solutions can be time-consuming and highly risky, expensive, and complicated. However, the following four techniques can help companies reduce the complexity and risk around their modernization efforts.
All COBOL to C# Solutions are Equal
It can be daunting for a company to sift through a set of sophisticated services and tools on the market to boost their modernization efforts. Manual modernization solutions often turn into an endless nightmare while the automated ones are saturated with solutions that generate codes that are impossible to maintain and extend once the migration is over. However, your IT department can still work with tools and services and create code that is easier to manage if it wants to capitalize on technologies such as DevOps.
Narrow the Focus
Most legacy systems are incompatible with newer systems. For years now, companies have passed legacy systems to one another without considering functional relationships and proper documentation features. However, a detailed analysis of databases and legacy systems can be useful in decision-making and risk mitigation in any modernization effort. It is fairly common for companies to uncover a lot of unused and dead code when they analyze their legacy inventory carefully. Those discoveries, however can help reduce the cost involved in project implementation and the scope of COBOL to C# modernization. Research has revealed that legacy inventory analysis can result in a 40% reduction of modernization risk. Besides making the modernization effort less complex, trimming unused and dead codes and cost reduction, companies can gain a lot more from analyzing these systems.
Understand Thyself
For most companies, the legacy system entails an entanglement of intertwined code developed by former employees who long ago left the organization. The developers could apply any standards and left behind little documentation, and this made it extremely risky for a company to migrate from a COBOL to C# solution. In 2013, CIOs teamed up with other IT stakeholders in the insurance industry in the U.S to conduct a study that found that only 18% of COBOL to C# modernization projects complete within the scheduled period. Further research revealed that poor legacy application understanding was the primary reason projects could not end as expected.
Furthermore, using the accuracy of the legacy system for planning and poor understanding of the breadth of the influence of the company rules and policies within the legacy system are some of the risks associated with migrating from COBOL to C# solutions. The way an organization understands the source environment could also impact the ability to plan and implement a modernization project successfully. However, accurate, in-depth knowledge about the source environment can help reduce the chances of cost overrun since workers understand the internal operations in the migration project. That way, companies can understand how time and scope impact the efforts required to implement a plan successfully.
Use of Sequential Files
Companies often use sequential files as an intermediary when migrating from COBOL to C# solution to save data. Alternatively, sequential files can be used for report generation or communication with other programs. However, software mining doesn’t migrate these files to SQL tables; instead, it maintains them on file systems. Companies can use data generated on the COBOL system to continue to communicate with the rest of the system at no risk. Sequential files also facilitate a secure migration path to advanced standards such as MS Excel.
Modern systems offer companies a range of portfolio analysis that allows for narrowing down their scope of legacy application migration. Organizations may also capitalize on it to shed light on migration rules hidden in the ancient legacy environment. COBOL to C# modernization solution uses an extensible and fully maintainable code base to develop functional equivalent target application. Migration from COBOL solution to C# applications involves language translation, analysis of all artifacts required for modernization, system acceptance testing, and database and data transfer. While it’s optional, companies could need improvements such as coding improvements, SOA integration, clean up, screen redesign, and cloud deployment.
The world of technology moves faster than the speed of light it seems. Devices are updated and software upgraded annually and sometimes more frequent than that. Society wants to be able to function and be as productive as they can be as well as be entertained “now”.
Software companies must be ready to meet the demands of their loyal customers while increasing their market share among new customers. These companies are always looking to the ingenuity and creativity of their colleagues to keep them in the consumer’s focus. But, who are these “colleagues”? Are they required to be young, twenty-somethings that are fresh out of college with a host of ideas and energy about software and hardware that the consumer may enjoy? Or can they be more mature with a little more experience in the working world and may know a bit more about the consumer’s needs and some knowledge of today’s devices?
Older candidates for IT positions face many challenges when competing with their younger counterparts. The primary challenge that most will face is the ability to prove their knowledge of current hardware and the development and application of software used by consumers. Candidates will have to prove that although they may be older, their knowledge and experience is very current. They will have to make more of an effort to show that they are on pace with the younger candidates.
Another challenge will be marketing what should be considered prized assets; maturity and work experience. More mature candidates bring along a history of work experience and a level of maturity that can be utilized as a resource for most companies. They are more experienced with time management, organization and communication skills as well as balancing home and work. They can quickly become role models for younger colleagues within the company.
Unfortunately, some mature candidates can be seen as a threat to existing leadership, especially if that leadership is younger. Younger members of a leadership team may be concerned that the older candidate may be able to move them out of their position. If the candidate has a considerably robust technological background this will be a special concern and could cause the candidate to lose the opportunity.
Demonstrating that their knowledge or training is current, marketing their experience and maturity, and not being seen as a threat to existing leadership make job hunting an even more daunting task for the mature candidate. There are often times that they are overlooked for positions for these very reasons. But, software companies who know what they need and how to utilize talent will not pass up the opportunity to hire these jewels.
Related:
H-1B Visas, the Dance Between Large Corporations and the Local IT Professional
Is a period of free consulting an effective way to acquire new business with a potential client?
Tech Life in Rhode Island
| Company Name | City | Industry | Secondary Industry |
|---|---|---|---|
| CVS Caremark Corporation | Woonsocket | Healthcare, Pharmaceuticals and Biotech | Personal Health Care Products |
| Textron Inc. | Providence | Manufacturing | Aerospace and Defense |
training details locations, tags and why hsg
The Hartmann Software Group understands these issues and addresses them and others during any training engagement. Although no IT educational institution can guarantee career or application development success, HSG can get you closer to your goals at a far faster rate than self paced learning and, arguably, than the competition. Here are the reasons why we are so successful at teaching:
- Learn from the experts.
- We have provided software development and other IT related training to many major corporations in Rhode Island since 2002.
- Our educators have years of consulting and training experience; moreover, we require each trainer to have cross-discipline expertise i.e. be Java and .NET experts so that you get a broad understanding of how industry wide experts work and think.
- Discover tips and tricks about Ruby Programming programming
- Get your questions answered by easy to follow, organized Ruby Programming experts
- Get up to speed with vital Ruby Programming programming tools
- Save on travel expenses by learning right from your desk or home office. Enroll in an online instructor led class. Nearly all of our classes are offered in this way.
- Prepare to hit the ground running for a new job or a new position
- See the big picture and have the instructor fill in the gaps
- We teach with sophisticated learning tools and provide excellent supporting course material
- Books and course material are provided in advance
- Get a book of your choice from the HSG Store as a gift from us when you register for a class
- Gain a lot of practical skills in a short amount of time
- We teach what we know…software
- We care…