Microsoft SQL Server Training Classes in Munich, Germany
Learn Microsoft SQL Server in Munich, Germany and surrounding areas via our hands-on, expert led courses. All of our classes either are offered on an onsite, online or public instructor led basis. Here is a list of our current Microsoft SQL Server related training offerings in Munich, Germany: Microsoft SQL Server Training
Microsoft SQL Server Training Catalog
Course Directory [training on all levels]
- .NET Classes
- Agile/Scrum Classes
- AI Classes
- Ajax Classes
- Android and iPhone Programming Classes
- Azure Classes
- Blaze Advisor Classes
- C Programming Classes
- C# Programming Classes
- C++ Programming Classes
- Cisco Classes
- Cloud Classes
- CompTIA Classes
- Crystal Reports Classes
- Data Classes
- Design Patterns Classes
- DevOps Classes
- Foundations of Web Design & Web Authoring Classes
- Git, Jira, Wicket, Gradle, Tableau Classes
- IBM Classes
- Java Programming Classes
- JBoss Administration Classes
- JUnit, TDD, CPTC, Web Penetration Classes
- Linux Unix Classes
- Machine Learning Classes
- Microsoft Classes
- Microsoft Development Classes
- Microsoft SQL Server Classes
- Microsoft Team Foundation Server Classes
- Microsoft Windows Server Classes
- Oracle, MySQL, Cassandra, Hadoop Database Classes
- Perl Programming Classes
- Python Programming Classes
- Ruby Programming Classes
- SAS Classes
- Security Classes
- SharePoint Classes
- SOA Classes
- Tcl, Awk, Bash, Shell Classes
- UML Classes
- VMWare Classes
- Web Development Classes
- Web Services Classes
- Weblogic Administration Classes
- XML Classes
- OpenShift Fundamentals
5 October, 2026 - 7 October, 2026 - Linux Troubleshooting
31 August, 2026 - 4 September, 2026 - RED HAT ENTERPRISE LINUX AUTOMATION WITH ANSIBLE
9 November, 2026 - 12 November, 2026 - DOCKER WITH KUBERNETES ADMINISTRATION
28 September, 2026 - 2 October, 2026 - Enterprise Linux System Administration
21 September, 2026 - 25 September, 2026 - See our complete public course listing
Blog Entries publications that: entertain, make you think, offer insight
One of the most anticipated features that came on the iPhone 4S was a new thing called: Siri. Zooming out before concentrating on Siri, mobile assistants were the new rage. Beforehand, people were fascinated by the cloud, and how you could store your files in the Internet and retrieve it from anywhere. You could store your file at home, and get it at your workplace to make a presentation. However, next came virtual assistants. When you’re in the car, it’s hard to send text messages. It’s hard to call people. It’s hard to set reminders that just popped into your head onto your phone. Thus, came the virtual assistant: a new way to be able to talk to your phone to be able to do what you want it to do, and in this case, text message, or call people, and many other features. Apple jumped onto the bandwagon with the iPhone 4S and came out with the new feature: Siri, a virtual assistant that is tailored to assist you in your endeavours by your diction.
Getting started with Siri
To get Siri in the first place, you need an iPhone 4S; although you may have the latest updates on your iPhone 4 or earlier, having an iPhone 4S means you have the hardware that is required to run Siri on your phone. Therefore, if you are interested in using Siri, check into getting an iPhone 4S, as they are getting cheaper every single day.
Not too long ago, Apple added something phenomenal to the iPhone OS: a dashboard screen. If you have a Macintosh computer, you may be familiar with the dashboard that is available (regularly) by pressing F4. Otherwise, you can draw similarities to your Windows 7 Dashboard on the right hand side of your desktop, that shows you updates on your applications and widgets you add to it. Finding your dashboard on your iPhone is just as easy: just put your finger on the top of your iPhone screen, and drag down.
Here, in your dashboard, you will see all of the updates that has been pushed into such by your applications that desire to send you messages: things like new text messages, new updates to your subscribed magazines, your messages on payment applications. If you have reviewed a message set by an application by tapping on it, that message will automatically become deleted. However, if you don’t desire to go into the application to delete it, simply tap in the top right on the bar that categorizes that particular application, and tap again to clear all of the messages set by that application, and clear up your dashboard.
But, your dashboard isn’t all about your application. You not only get your messages, but you get important information set by default applications, such as the weather. If you don’t feel like scouting out your weather application amidst all your applications you have downloaded, simply go into your dashboard, and find out the forecast for the whole week, just by a simple swipe. Not only that, tickers for your stocks are displayed near the bottom of the dashboard.
Information Technology is one of the most dynamic industries with new technologies surfacing frequently. In such a scenario, it can get intimidating for information technology professionals at all levels to keep abreast of the latest technology innovations worth investing time and resources into.
It can therefore get daunting for entry and mid-level IT professionals to decide which technologies they should potentially be developing skills. However, the biggest challenge comes for senior information technology professionals responsible for driving the IT strategy in their organizations.
It is therefore important to keep abreast of the latest technology trends and get them from reputable sources. Here are some of the ways to keep on top of the latest trends in Information Technology.
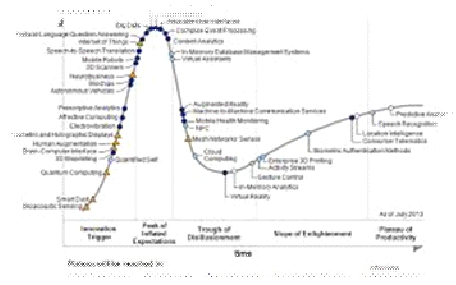
· Subscribe to leading Analyst Firms: If you work for a leading IT organization, chances are that you already have subscription to leading IT analyst firms notably Gartner and Forrester. These two firms are some of the most recognized analyst firms with extensive coverage on almost every enterprise technology including hardware and software. These Analyst firms frequently publish reports on global IT spending and trends that are based on primary research conducted on vendors and global CIOs & CTOs. However, subscription to these reports is very expensive and if you are a part of a small organization you may have issues securing access to these reports. One of the most important pieces of research published by these firms happens to be the Gartner Hype Cycle which plots leading technologies and their maturity curve.Even if you do not have access to Gartner research, you can hack your way by searching for “Gartner Hype Cycle” on Google Images and you will in most cases be able to see the plots similar to the one below

Net Neutrality
You may have heard about net neutrality over the years. Recently, the concept has gone through some changes, and many would consider its underlying principles to be in danger of corruption or dissolution. However, the technical nature of net neutrality ethics makes it difficult to understand for the layperson. Read on, and the central themes and controversies surrounding the principle will be outlined and explained for your convenience.
The Theme
training details locations, tags and why hsg
The Hartmann Software Group understands these issues and addresses them and others during any training engagement. Although no IT educational institution can guarantee career or application development success, HSG can get you closer to your goals at a far faster rate than self paced learning and, arguably, than the competition. Here are the reasons why we are so successful at teaching:
- Learn from the experts.
- We have provided software development and other IT related training to many major corporations in Germany since 2002.
- Our educators have years of consulting and training experience; moreover, we require each trainer to have cross-discipline expertise i.e. be Java and .NET experts so that you get a broad understanding of how industry wide experts work and think.
- Discover tips and tricks about Microsoft SQL Server programming
- Get your questions answered by easy to follow, organized Microsoft SQL Server experts
- Get up to speed with vital Microsoft SQL Server programming tools
- Save on travel expenses by learning right from your desk or home office. Enroll in an online instructor led class. Nearly all of our classes are offered in this way.
- Prepare to hit the ground running for a new job or a new position
- See the big picture and have the instructor fill in the gaps
- We teach with sophisticated learning tools and provide excellent supporting course material
- Books and course material are provided in advance
- Get a book of your choice from the HSG Store as a gift from us when you register for a class
- Gain a lot of practical skills in a short amount of time
- We teach what we know…software
- We care…